
I am a 4th-year Ph.D. candidate at Harbin Institute of Technology (Shenzhen), under the supervision of Haijun Zhang. Now I am doing research under the supervision of Xin Li and Ming-Hsuan Yang.
🔥 News
- 2025.07: 🎉🎉 Winner of the VOTS 2025 Challenge (VOTS Track, VOTS-RT Track, VOTSt Track)
- 2025.01: 🎉🎉 One paper is accepted to ICLR 2025
- 2024.08: 🎉🎉 Winner of the LSVOS V6 Challenge (VOS Track)
- 2024.07: 🎉🎉 Winner of the VOTS 2024 Challenge (VOTS Track)
- 2024.07: 🎉🎉 One paper is accepted to ECCV 2024
- 2024.06: 🎉🎉 Winner of the 3th PVUW workshop (MOSE Track)
- 2024.03: 🎉🎉 One paper is accepted to TMM
- 2023.08: 🎉🎉 2nd Place of 5th LSVOS Challenge
📝 Publications
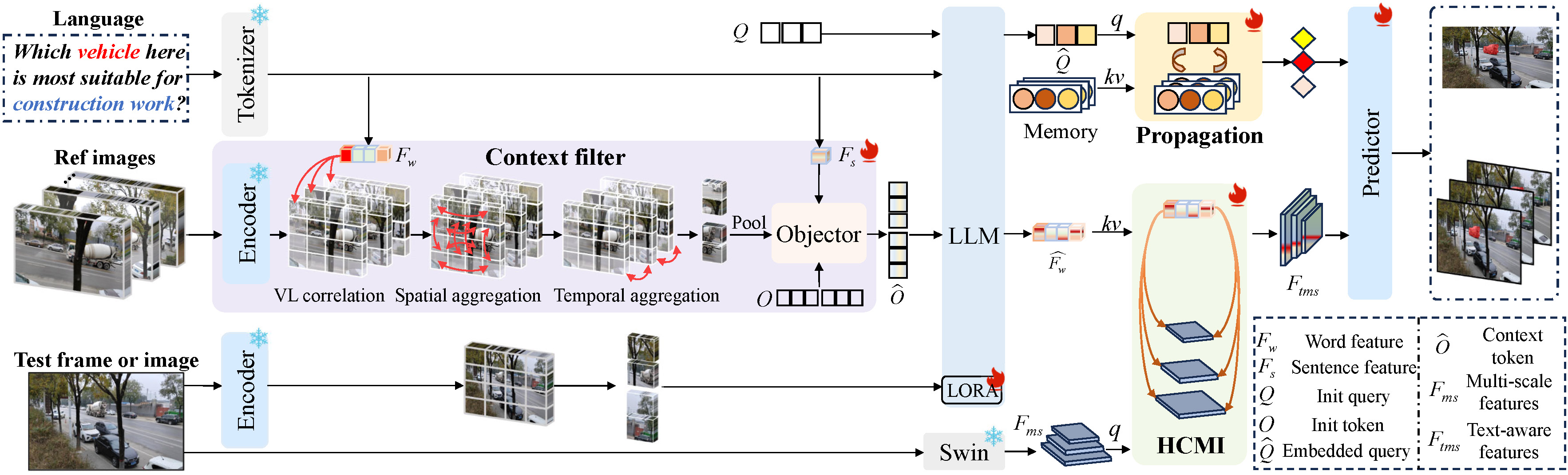
Referring and Reasoning Segmentation via Learning Contextual Instructions [[pdf]][[code]]
Deshui Miao, Yameng Gu, Zhenyu He, Xin Li, Qingfang Zheng, Ming-Hsuan Yang
- We explore the learning of contextual spatial details and consistent temporal aggregation in an end-to-end manner. Specifically, we propose a context filter for aggregating object-level information on semantic, spatial, and temporal dimensions to inject rich spatial-temporal features into the MLLMs. Subsequently, we develop a visual language correlation to effectively capture local and global spatial details. In addition, we introduce a propagation module with an object query memory to enhance inter-frame consistency for maintaining the previous target representation. The proposed model, named ContextSeg, achieves state-of-the-art performance in various image and video segmentation tasks, showcasing its spatial understanding and temporal reasoning abilities.
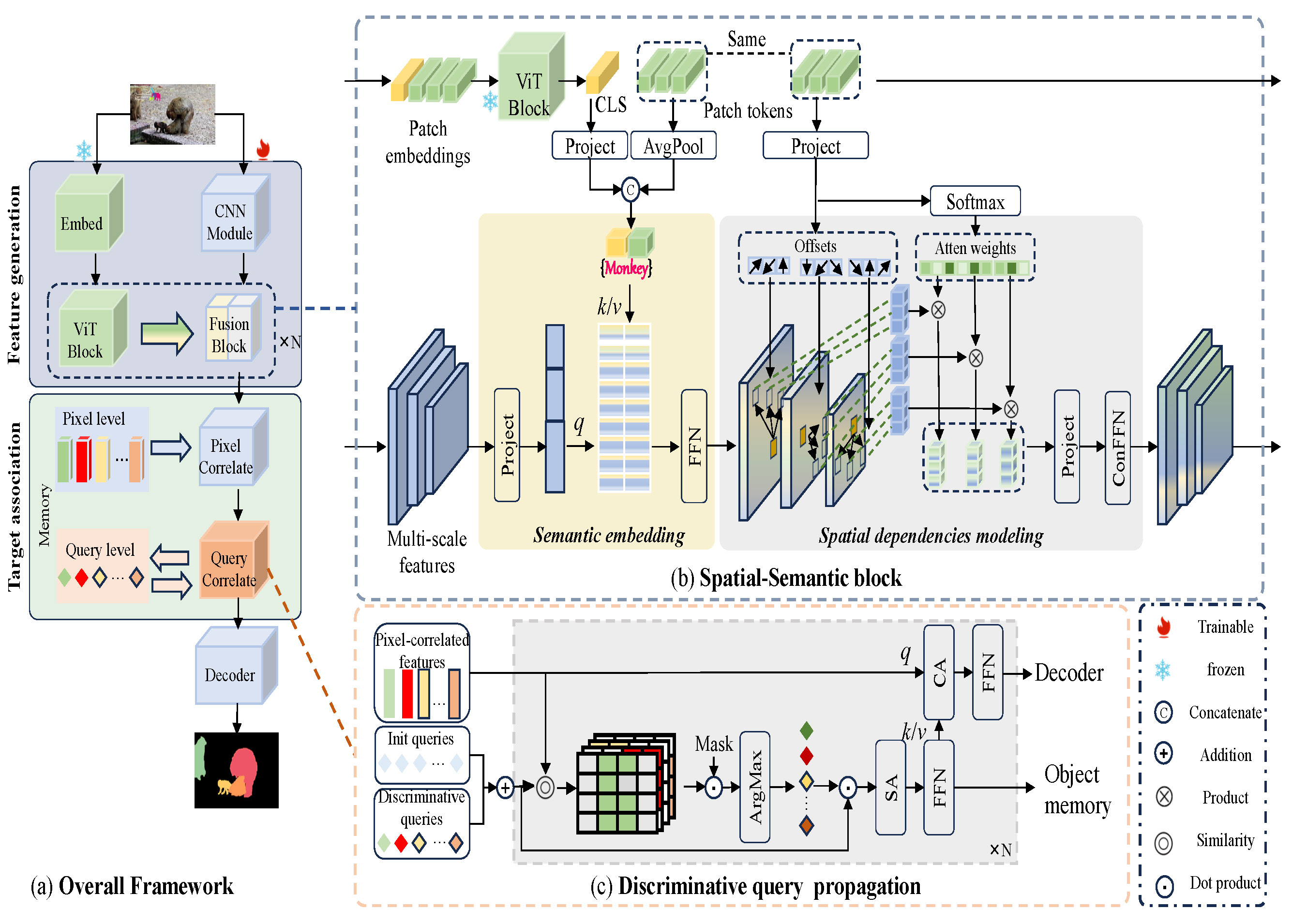
Learning Spatial-Semantic Features for Robust Video Object Segmentation [pdf][code]
Xin Li, Deshui Miao, Zhenyu He, Yaowei Wang, Huchuan Lu, Ming-Hsuan Yang
(ICLR) 2025
- In this paper, we propose a robust video object segmentation framework equipped with spatial-semantic features and discriminative object queries to address the above issues. Specifically, we construct a spatial-semantic network comprising a semantic embedding block and spatial dependencies modeling block to associate the pretrained ViT features with global semantic features and local spatial features, providing a comprehensive target representation. In addition, we develop a masked cross-attention module to generate object queries that focus on the most discriminative parts of target objects during query propagation, alleviating noise accumulation and ensuring effective long-term query propagation.
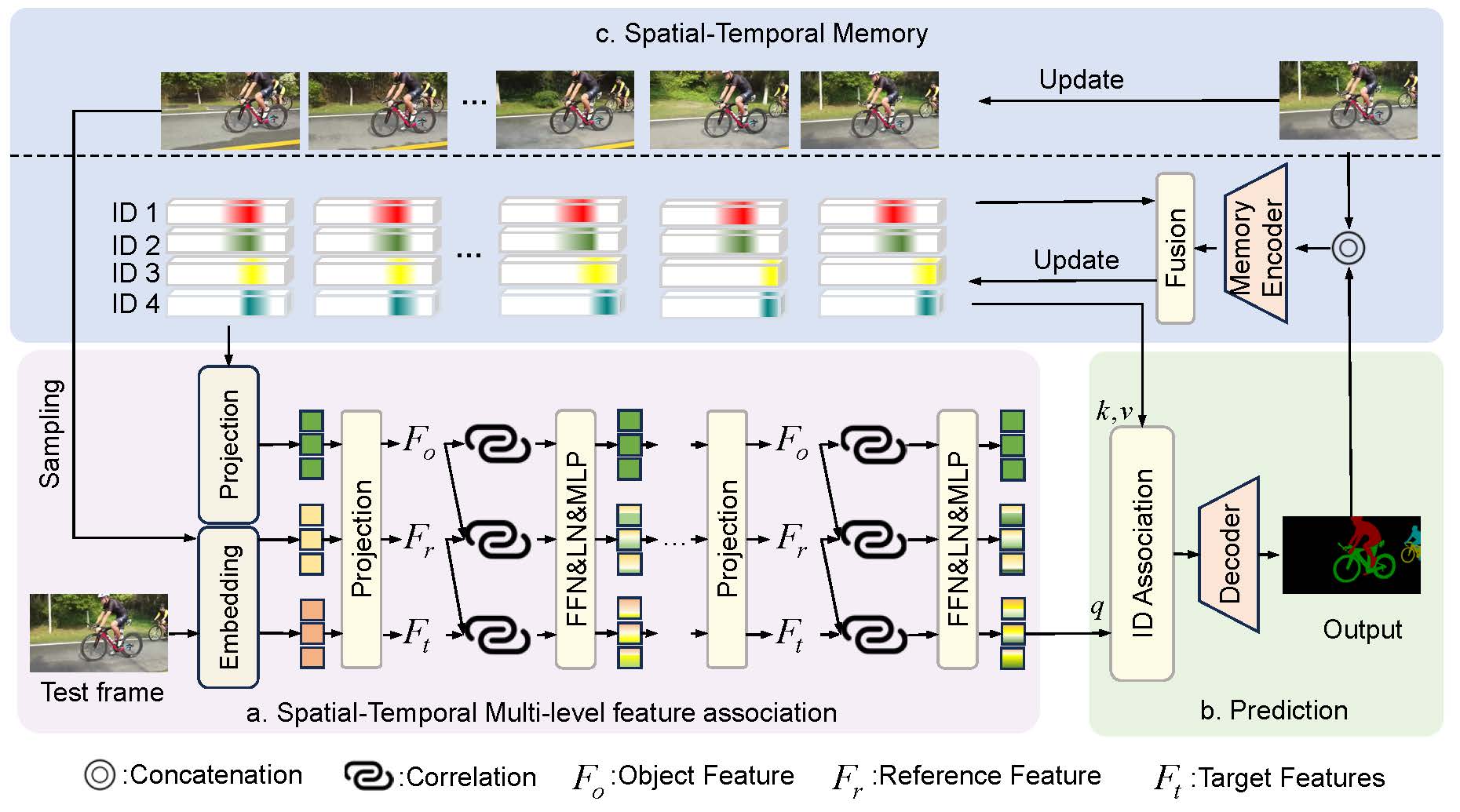
Spatial-Temporal Multi-level Association for Video Object Segmentation [pdf][code]
Deshui Miao, Xin Li, Zhenyu He, Huchuan Lu, Ming-Hsuan Yang
European Conference on Computer Vision (ECCV) 2024
- we propose a spatial-temporal memory to assist feature association and temporal ID assignment and correlation. We evaluate the proposed method by conducting extensive experiments on numerous video object segmentation datasets, including DAVIS 2016/2017 val, DAVIS 2017 test-dev, and YouTube-VOS 2018/2019 val. The favorable performance against the state-of-the-art methods demonstrates the effectiveness of our approach.
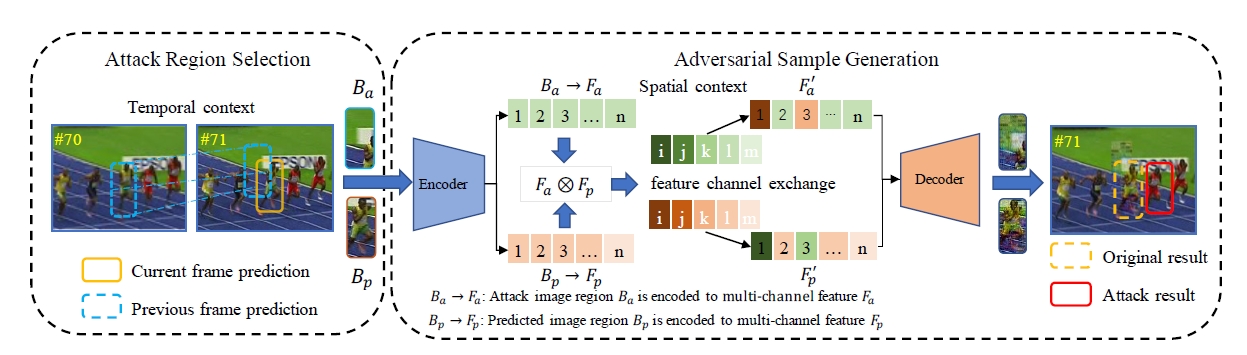
Context-Guided Black-Box Attack for Visual Tracking [pdf]
Xingsen Huang, Deshui Miao, Hongpeng Wang, Yaowei Wang, Xin Li
IEEE Transactions on Multimedia (TMM)
- We propose a context-guided black-box attack method to investigate the robustness of recent advanced deep trackers against spatial and temporal interference.
🎖 Services
Reviewer of NIPS 2024.
🎖 Honors and Awards




2nd Place Solution for the LSVOS Challenge 2023: Video Object Segmentation [pdf]
💻 Internships
- 2021.03 - 2022.06, Sensetime, Beijing, China.
- 2021.06 - 2022.05, Alibaba AI Research (GaoDe map), Beijing, China.
- 2022.09 - 2025.04, PengCheng Laboratory (supervised by Xin Li),Shenzhen, China.
- 2025.05 - 2025.08, Tencent 青云计划, Shenzhen, China.